
2023년 12월, AMD의 MI300 AI 전용 칩셋이 발표되면서 주가가 크게 상승했습니다. 엔비디아가 주도해온 AI 칩 시장에 처음으로 경쟁 제품이 등장하자 투자자들은 크게 열광했습니다. 특히, MI300이 엔비디아의 H100과 비슷하거나 더 나은 성능을 보인다는 발표에 시장은 크게 고무되었습니다.
AMD의 MI300 시리즈에는 두 가지 모델인 MI300X와 MI300A가 있습니다. 이들은 각각 AI와 HPC 시장을 겨냥해 개발되었습니다. 통합 CPU가 필요한 경우 MI300A를, 고성능 GPU 기능을 중시하는 경우 MI300X를 선택할 수 있도록 설계되었습니다.
1. MI300X
MI300X는 전통적인 GPU 모델로, Nvidia의 H100과 직접 경쟁하도록 설계되었습니다. GPU 성능에 중점을 둔 이 모델은 특히 강력한 GPU 계산이 필요한 HPC 및 AI 작업에 매우 적합합니다. MI300A에 비해 더 큰 메모리 용량(192GB의 HBM3)을 제공하며, 이는 대규모 언어 모델과 같은 AI 작업에서 추론을 실행하는 데 적합합니다.
MI300X와 H100(엔비디아)의 스펙 및 성능을 비교
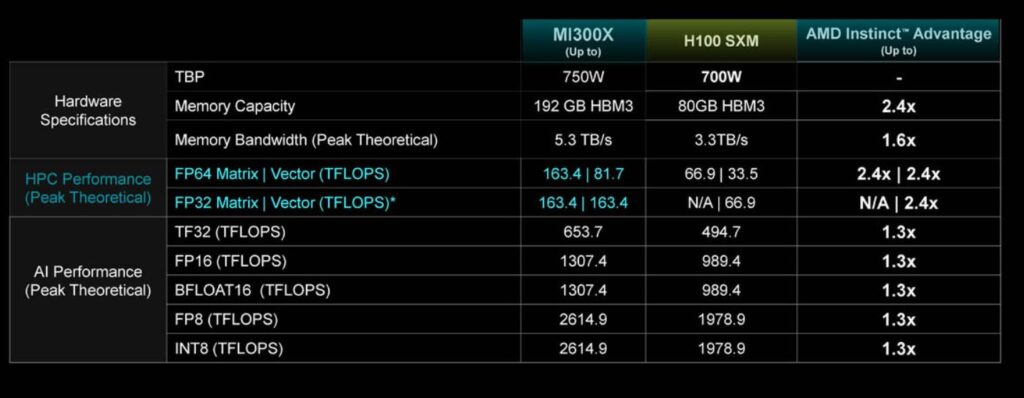
출처: AMD
MI300X는 메모리 측면에서 H100에 비해 큰 강점을 지니고 있습니다. 둘 다 HBM3 메모리를 장착하고 있지만, MI300X는 192GB로, 80GB인 H100에 비해 2.4배 더 높은 용량을 갖습니다. 대역폭 면에서도 MI300X는 5.3 TB/s로, H100의 3.3TB/s에 비해 60% 개선되었습니다.
이러한 높은 메모리 용량과 속도는 MI300X가 인퍼런싱(추론)에서 강점을 보이는 데 기여합니다. LLAMA 2-70B 추론 벤치마크에서 MI300X는 H100 대비 약 40% 향상된 레이턴시를 보여주며, 이는 높은 메모리 대역폭 덕분에 빠른 데이터 전송과 연산이 가능하기 때문입니다.
AI 훈련 성능 측면에서 AMD MI300X와 Nvidia H100의 강점
AMD는 MI300X가 AI 훈련 작업에서 Nvidia H100과 유사한 성능을 제공한다고 주장합니다. MI300X는 AI 추론 작업에서도 뛰어나며, H100에 비해 AI 추론에서 최대 1.6배 더 높은 성능을 제공합니다. 또한, MI300X는 H100에 비해 2.4배 더 많은 메모리 용량, 1.6배 더 많은 메모리 대역폭 및 FP8 및 FP16 컴퓨트에서 1.3배 더 많은 TFLOPS를 제공합니다.
반면 Nvidia는 H100이 특히 AI 가속화 측면에서 AMD MI300X보다 2배 빠르다고 주장합니다. H100의 AI 훈련 작업 성능 지표와 능력은 강조되지만, AI 훈련에서 H100과 MI300X 간의 직접적인 비교 데이터는 출처에서 자세히 설명되지 않았습니다.

AMD MI300X의 한계는?
이론적 성능 대비 실제 성능:
MI300X는 이론적으로 H100에 비해 FP8 FLOPS에서 30% 높고, 메모리 대역폭이 60% 더 높으며, 메모리 용량이 두 배 이상입니다. 그러나 실제 벤치마크 결과는 이러한 이론적 성능을 완전히 반영하지 못하고 있습니다. MI300X의 추론 작업 성능 우위는 이론적 사양 대비 10%에서 20% 수준에 불과합니다.
소프트웨어 스택 제한:
MI300X의 성능에서 중요한 부분은 소프트웨어 스택이 이론적 FLOPS의 30% 미만을 달성한다는 것입니다. 반면 Nvidia의 경우 종종 이론적 FLOPS의 약 40%를 달성합니다. 이러한 차이는 AMD가 하드웨어 기능을 완전히 활용하는 데 어려움을 겪고 있음을 시사합니다.
2. MI300A
AMD의 첫 번째 데이터 센터 APU(가속 처리 장치)인 MI300A는 AI 및 HPC 응용 프로그램을 위한 제품입니다. 이 제품은 AMD의 CDNA 3 데이터 센터 GPU 컴퓨팅 아키텍처와 Zen 4 CPU 칩렛(24개의 Genoa 코어)을 결합하며, 128GB의 공유 통합 HBM3 메모리로 CPU와 GPU 가속기에 모두 액세스할 수 있도록 되어 있습니다. MI300A는 총 13개의 칩렛으로 구성되어 있습니다.
MI300A는 Grace Hopper와 함께 추론 분야에서 강점
MI300A와 Grace Hopper는 AI 추론 작업 부하에서 탁월한 성능을 발휘합니다. 컴퓨터 비전, 음성 인식, 의료 영상, 추천 시스템, 그리고 대규모 언어 모델(LLM)과 같은 다양한 도메인의 추론 작업에 최적화되어 있습니다. 뿐만 아니라, AI 훈련 및 미세 조정 분야에서도 뛰어난 성능을 보입니다. Grace Hopper 플랫폼은 대규모 언어 모델의 훈련 및 미세 조정을 수행할 수 있으며, 이는 수백억 개의 파라미터를 가진 모델을 처리하는 데 적합합니다.
가속 컴퓨팅 분야에서도 MI300A는 뛰어난 성능
Grace Hopper는 고대역폭과 메모리 일관성 아키텍처를 갖춘 설계로 가속 컴퓨팅을 위해 최적화되어 있으며, 이는 AI 훈련 및 추론 작업을 모두 포함합니다.
CPU 아키텍처와 통합 측면에서 경쟁우위
통합 메모리 아키텍처:
MI300A는 단일 HBM3 풀을 가진 통합 메모리 레이아웃을 특징으로 합니다. 이 설계를 통해 CPU가 데이터를 변환한 후에 GPU가 동일한 메모리에 직접 액세스할 수 있습니다. 반면에, NVIDIA Grace Hopper는 Arm CPU(와 LPDDR 메모리)와 H100/H200 GPU(와 HBM)에 대해 통합되지 않은 별도의 메모리 풀을 가지고 있습니다.
CPU 통합 및 코어 수:
MI300A는 24개의 Zen 4 CPU 코어와 48개의 스레드를 통합하고 있으며, 이는 각각 별도의 캐시 및 코어 IP 풀에 분산되어 있습니다. 이러한 통합 수준은 NVIDIA의 Grace Hopper보다 더 앞서 있다고 평가됩니다. 또한, AMD의 CPU와 GPU 조합은 전력 소모 전송을 피하기 위해 CPU와 GPU 사이의 PCB를 사용하지 않습니다.
성능 및 효율성:
특히 HPC 특정 워크로드에서, MI300A는 통합 메모리 레이아웃, GPU 성능, 전체 메모리 용량 및 대역폭으로 인해 최대 4배의 성능 향상을 보여주었습니다. 또한, 와트당 최대 2배의 성능을 제공합니다.
3. AMD의 AI소프트웨어 플랫폼 향상을 위한 노력
AMD는 AI 성장 전략의 일환으로 오픈 소스 AI 소프트웨어 스타트업인 Nod.AI를 인수했습니다. 이 움직임은 AMD의 오픈 소스 AI 제품을 강화하고 Nvidia와의 경쟁에서 우위를 점하기 위한 것입니다.
AI 소프트웨어 능력 확장:
Nod.AI 인수는 AI 고객에게 AMD 하드웨어에 최적화된 빠르고 효율적인 AI 모델 배포를 가능케 하는 오픈 소프트웨어를 제공하는 목적입니다. Nvidia는 역사적으로 AI GPU 분야를 주도해왔지만, AMD의 인수, 특히 Nod.AI 인수는 AI 컴퓨팅 분야에서 Nvidia의 지배력에 도전하기 위한 전략의 일부입니다.
Nvidia의 H100이 특정 측면에서 더 빠르다는 주장이 있지만, AMD의 MI300X는 경쟁력을 갖추었으며 특히 AI 추론 분야에서 중요한 진전을 이루었습니다. 또한, Nod.AI의 전략적 인수는 AMD가 하드웨어 뿐만 아니라 AI 소프트웨어 분야에서도 Nvidia와 경쟁 의지를 나타냅니다.
4. MI300의 가격 경쟁력
Nvidia H100의 가격은 스펙에 따라 다양하며, 대략 칩당 가격이 $30,000 ~$42,000으로 알려져 있습니다. 이 가격은 판매자와 H100 모델의 구체적인 구성에 따라 다를 수 있습니다.
아직 AMD MI300X의 경우, 접근한 출처에서 정확한 가격 정보를 제공하지 않고 있습니다. AMD가 MI300X를 Nvidia와 경쟁할 수 있도록 포지셔닝하고 있으며 가격 측면에서도 경쟁력을 갖추려는 의도가 있음을 고려할 때, H100대비 월등히 낮은 가격에 출시될 것으로 전망됩니다.
5. MI300에 삼성전자의 HBM3가 탑재될 예정
삼성전자는 HBM2E 때까지는 높은 시장점유율을 기록하였지만, 엔비디아의 H100에 HBM3 공급에 실패하면서 엔비디아에 이를 독점 공급한 하이닉스에게 뒤쳐지게 되었습니다. 국내 언론들의 보도에 따르면, 삼성의 HBM3 칩은 MI300에 공급될 것으로 보입니다. 특히 삼성의 HBM 생산능력이 내년에 2배 이상 급등하기 때문에 시장참여자들의 우려도 점차 완화되고 있습니다. AMD는 HBM을 제작할 수 있는 모든 제조사 (삼성, 하이닉스, 마이크론)로 부터 칩을 공급받을 예정이라고 합니다. 이와 더불어, 삼성의 HBM3가 엔비디아의 성능검사를 통과했다는 뉴스도 보도되었습니다.
6. 결론
AMD의 MI300X는 이론적으로 H100 을 능가하는 사양을 보여주지만, 현재 소프트웨어 한계와 실제 벤치마크에서의 성능으로 인해 Nvidia의 H100을 훈련에서 능가할 수 있는지에 대해 전문가들은 신중한 태도를 보이고 있습니다.
그러나 MI300X는 시장에서, 특히 추론 응용 분야에서 발전을 보이고 있으며, AI 분야의 주요 기업들에 의해 채택되고 있습니다. OpenAI와 Microsoft와 같은 회사들은 추론을 위해 AMD MI300을 대량으로 사용할 계획입니다. AMD의 MI300A의 경우, CPU에서 엔비디아 대비 강점을 가지고 있기 때문에, 트레이닝과 인퍼런싱을 통합하여 운영하는 서버시장에서 MI300A이 강점을 가질 수 있습니다.
AI 시장이 더 광범위하게 성장하기 위해서는, 제반 비용이 저렴해져야 합니다. 현재 엔비디아가 컴퓨팅 칩셋을 독점하기 때문에, AI 서버를 구성하는 비용이 높습니다. AMD의 MI300 시리즈 출시로 엔비디아의 독점구조가 깨질 것으로 전망됩니다. 실제 칩이 출시되지 않았지만, PC 시장에서 AMD의 GPU와 APU는 엔비디아와 수십년간 경쟁해 왔기 때문에 성능에 대한 우려도 적은 편입니다.
3 thoughts on “AMD의 AI칩 MI300은 돌풍일까? 찻잔속의 태풍일까?”
Comments are closed.